Глава 2 Встраиваем LLM модель в Telegram бота
В первой главе мы создали интеллект и дали ему «лицо» в виде Shiny-приложения. Но настоящий ассистент аналитика должен быть доступен в один клик прямо в смартфоне.
В этой главе мы переместим наш AI-движок в Telegram. Главный вызов здесь — многопользовательская среда. Мы разберем, как сделать так, чтобы бот не путал контекст диалогов разных людей и помнил историю переписки даже после перезагрузки сервера. Мы превратим Telegram из простого мессенджера в полноценную точку доступа к вашему кастомному ИИ.
Если вы не знакомы с принципами разработки telegram ботов на языке R то можете пройти курс “Разработка telegram ботов на языке R”.
2.1 Видео
2.1.1 Тайм коды
- 00:00 — О чём это видео
- 00:46 — Генерация API ключа
-
02:20 — Введение в пакет
ellmer - 03:20 — Создаём объект чата
- 06:44 — Извлечение структурированных данных из текста
- 10:35 — Классификация текста с помощью LLM моделей
- 13:53 — Интеграция LLM моделей со сторонними API
- 18:33 — Как интегрировать LLM модель в Telegram-бота
- 23:27 — Как сохранять состояние чатов (Session Handling)
- 26:24 — Как дообучить бота своими данными (System Prompt)
- 28:58 — Заключение
2.3 Конспект
2.3.1 Интеграция LLM модели в бот
Давайте разберёмся с тем, как добавить весь описанный в первой главе функционал в Telegram бота. Основная сложность с которой вы можете столкнуться это то, как хранить одновременно отдельные объекты chat для каждого отдельного чата в Telegram. Т.к. если вы просто создадите один объект чата, и в него будут прилетать сообщения из разных telegram чатов, и разных пользователей, то контекст чата будет запутан, и соответвенно модель в чате не сможет осмысленно связать все входящие сообщения, и качество ответов будет оставлять лучшего. Поэтому одним из вариантов хранения информация о разных чатах является создание списка, в котором в виде отдельных элементов будут хранится разные объекты чата для разных telegram чатов, название каждого элемента списка будет соответствовать идентификатору чата в telegram.
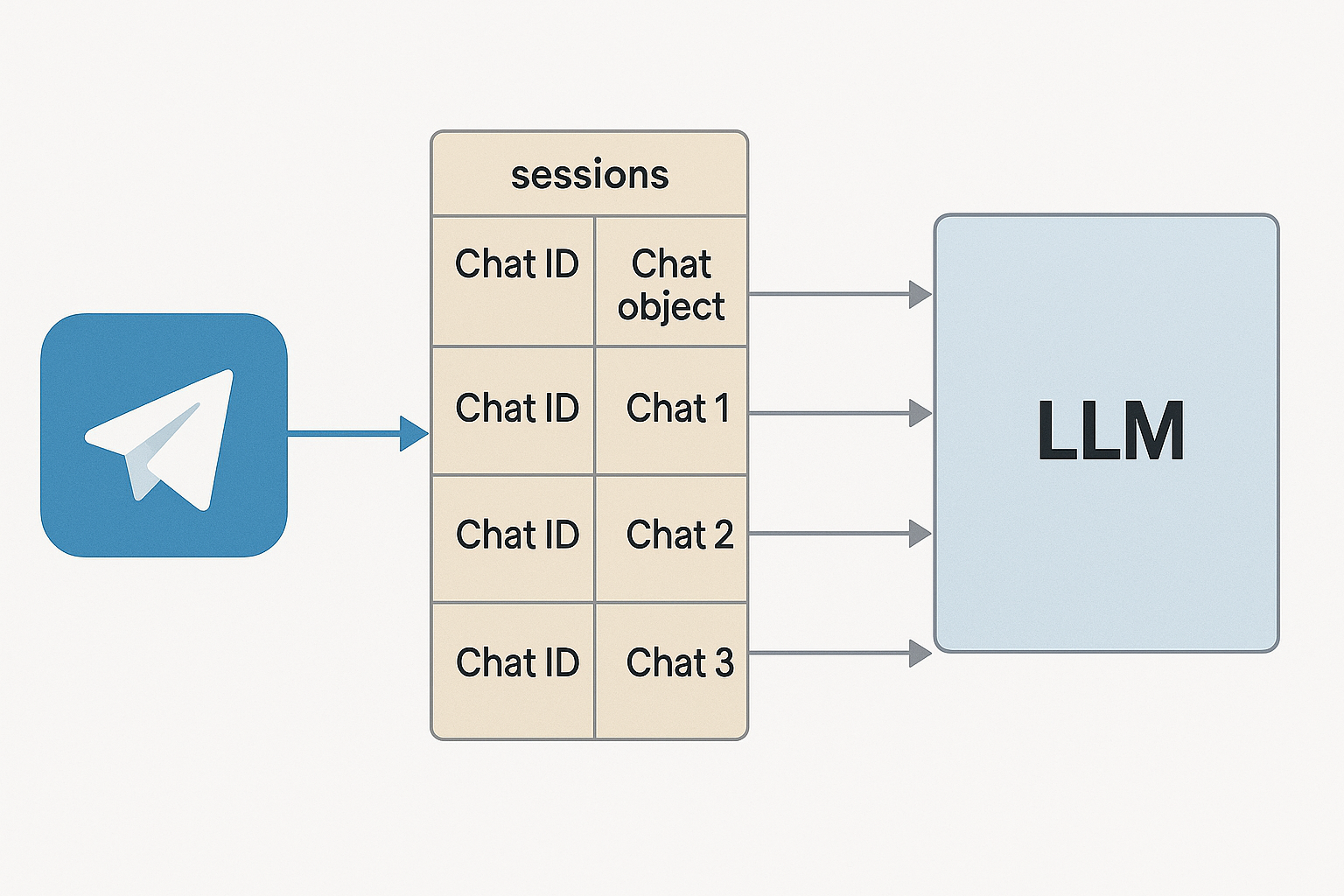
Простейший пример кода, для интеграции LLM модели в telegram бот выглядит так:
library(telegram.bot)
library(ellmer)
# Создаём глобальную переменную для хранения сессий
# в которую будут добавляться новые чаты
sessions <- list()
# Handler для команды /start
start_handler <- function(bot, update) {
chat_id <- update$message$chat$id
# Создаём новый чат-объект для пользователя с уникальным чатом
chat <- chat_google_gemini(
system_prompt = "
Ты специалист по разработке кода и анализу данных на языке R,
в этом чате помогаешь с разработкой кода на R. Твои ответы должны занимать не более 3000 символов.
",
api_args = list(
generation_config = list(
max_output_tokens = 1500
)
)
)
# Сохраняем чат-объект в глобальной переменной sessions
sessions[[as.character(chat_id)]] <<- chat
bot$sendMessage(chat_id = chat_id, text = "Здравствуйте, чем могу вам помочь?")
}
# Handler для текстовых сообщений
message_handler <- function(bot, update) {
chat_id <- update$message$chat$id
# Получаем чат-объект для пользователя
chat <- sessions[[as.character(chat_id)]]
# Если чат не найден то просим выполнить команду start для его запуска
if (is.null(chat)) {
bot$sendMessage(chat_id = chat_id, text = "Используйте /start для начала AI чата.")
return(NULL)
}
# текст запроса
user_message <- update$message$text
# отправляем запрос пользователя в LLM
response <- chat$chat(user_message, echo = FALSE)
# отправляем в чат полученный от LLM ответ
bot$sendMessage(
chat_id = chat_id,
text = response,
parse_mode = 'markdown'
)
}
# Инициализируем бот и добавляем обработчики
updater <- Updater(bot_token('TEST'))
# Обработчики
h_start <- CommandHandler("start", start_handler)
h_msgs <- MessageHandler(message_handler, MessageFilters$text)
updater <- updater + h_start + h_msgs
# Запускаем бота
updater$start_polling()Безопасность прежде всего: Обратите внимание на функцию
bot_token(). Никогда не вставляйте токен бота строкой прямо в код. Самый надежный способ — прописать его в файле.Renvironпод именемR_TELEGRAM_BOT_TEST. Подробнее о том, почему это важно и как это настроить, смотрите в уроке “Работа с секретными данными на языке R”.
Что делает этот код и как он устроен:
В этом примере мы создаём Telegram-бота, который использует LLM-модель через пакет ellmer и умеет вести отдельные диалоги с каждым пользователем, сохраняя контекст общения.
Инициализация переменной sessions: В начале мы создаём глобальный список sessions, куда будут добавляться объекты чата
chat_google_geminiдля каждого Telegram-пользователя. Ключом в этом списке будет ID Telegram-чата (chat_id). Это позволяет хранить независимый LLM-контекст для каждого пользователя.Обработчик команды /start: Когда пользователь впервые запускает бота командой
/start, срабатываетstart_handler. В нём:
- Получается
chat_idпользователя. - Создаётся новый объект
chat_google_geminiс заданнымsystem_prompt.В prompt задаётся роль модели: помощник по разработке на языке R. - Так же мы ограничиваем максимальную длинну ответа от LLM передав через
api_argsпараметрmax_output_tokens, поскольку в telegram есть лимит на длинну сообщения в 4096 символов.api_args- аргумент, который позволяет передавать в запросе различные параметры, такие как температура, максимальная длинна ответа и так далее, набор этих параметров у каждой модели свой. Напрмиер Gemini позволяет вам управлять поведением модели через такие параметры как:-
temperature- значение от 0.0 до 1.0, отвечает за креативность модели, более низкие значение надо устанавливать если от модели требуются точные ответы (разработка кода, математические вычисления), и более высокие для решения креативных задач (написание песен, статей) -
topK- Это первый фильтр. Модель смотрит на все слова в своем словаре и отбирает только топ лучших в зависимости от указанного значения, 1 - «Жадный выбор». Модель берет только одно самое вероятное слово, 3 - Модель выбирает только из тройки лидеров. -
topP- Это второй фильтр, который работает вместе с Top-K. Модель складывает вероятности слов-лидеров, пока не наберет нужную сумму. Диапазон от 0.0 до 1.0 (1.0 пропускает 100% всех слов).
-
- Этот объект сохраняется в список sessions, где ключом служит chat_id.
- Пользователю отправляется приветственное сообщение.
- Обработчик текстовых сообщений: Этот обработчик вызывается каждый раз, когда пользователь пишет что-то в чат. Внутри:
- Получаем
chat_idи по нему — соответствующий объект изsessions. - Если объект чата не найден (например, пользователь не вызвал
/start), то бот просит сначала это сделать. - Если всё ок — берём текст сообщения пользователя и отправляем его в LLM через
chat$chat(). - Полученный ответ от модели возвращается пользователю в Telegram.
- Запуск бота:
Далее создаётся объект
Updaterс токеном бота, к нему добавляются два обработчика: для команды/startи для всех обычных сообщений. Затем вызываетсяstart_polling(), чтобы бот начал слушать входящие сообщения.
В чём суть логики?
Главное в этом подходе — поддержка сессий для каждого пользователя. Благодаря списку sessions мы можем вести независимые диалоги с разными пользователями одновременно. Каждый chat_gemini живёт в своей “ячейке” и помнит контекст диалога. Это особенно важно для того, чтобы LLM не путала запросы между разными пользователями, и могла давать максимально точные и уместные ответы.
Обратите внимание, что в системном промпте я отдельно указал “Твои ответы должны занимать не более 3000 символов.”, это сделано для того, что полученный от модели ответ помещался в одно сообщение telegram, которое на данный момент имеет лимит в 4096 символов.
Приведённый выше бот будет хранить все чаты в рамках одной своей сессии, после перезапуска все чаты будут удалены из его памяти. Если вам нужен бот, который будет хранить информацию о всех чатах между сессиями то объекты чата надо хранить в виде локальных rds файлов. Для реализации надо:
- Написать функции для сохранения и записи объектов чатов в RDS файлы
- Доработать функции start_handler() и message_handler() так, что бы они читали и сохраняли объекты чата в отдельные RDS файлы.
Сохраним код функций для работы с RDS файлами в отдельный session_func.R файл.
save_chat <- function(chat_id, chat_object) {
file_path <- file.path("chat_sessions", paste0(chat_id, ".rds"))
saveRDS(chat_object, file_path)
}
load_chat <- function(chat_id) {
file_path <- file.path("chat_sessions", paste0(chat_id, ".rds"))
if (file.exists(file_path)) {
return(readRDS(file_path))
} else {
return(NULL)
}
}И доработаем код бота:
library(telegram.bot)
library(ellmer)
# Загрузка функций чтения объектов чата
source('session_func.R')
# Handler для команды /start
start_handler <- function(bot, update) {
chat_id <- update$message$chat$id
# Проверяем был ли ранее создан чат
chat <- load_chat(chat_id)
# Создаём новый чат-объект для пользователя с уникальным чатом
if (is.null(chat)) {
chat <- chat_gemini(
system_prompt = paste(readLines(here::here('system_prompt.md')), collapse = "\n"),
api_args = list(
generation_config = list(
max_output_tokens = 1500
)
)
)
# сохраняем объект чата
save_chat(chat_id, chat)
}
bot$sendMessage(chat_id = chat_id, text = "Здравствуйте, чем могу вам помочь?")
}
# Handler для текстовых сообщений
message_handler <- function(bot, update) {
chat_id <- update$message$chat$id
# Получаем чат-объект для пользователя
chat <- load_chat(chat_id)
# Если чат не найден то просим выполнить команду start для его запуска
if (is.null(chat)) {
bot$sendMessage(chat_id = chat_id, text = "Используйте /start для начала AI чата.")
return(NULL)
}
# текст запроса
user_message <- update$message$text
# отправляем запрос пользователя в LLM
response <- chat$chat(user_message, echo = FALSE)
# сохраняем объект чата
save_chat(chat_id, chat)
# отправляем в чат полученный от LLM ответ
bot$sendMessage(
chat_id = chat_id,
text = response,
parse_mode = 'markdown'
)
}
# Инициализируем бот и добавляем обработчики
updater <- Updater(bot_token('TEST'))
# Обработчики
h_start <- CommandHandler("start", start_handler)
h_msgs <- MessageHandler(message_handler, MessageFilters$text)
updater <- updater + h_start + h_msgs
# Запускаем бота
updater$start_polling()Как изменилась логика работы бота В этой версии бота добавлена долговременная память — теперь каждый чат сохраняется в отдельный .rds-файл, а значит, бот не забывает переписку после перезапуска.
Основные изменения:
Загрузка и сохранение сессий: Вместо хранения объектов
chat_geminiв оперативной памяти (в списке sessions) теперь используется файловая система. Добавлены функцииload_chat()иsave_chat(), которые читают и записывают объекты чата в .rds-файлы (по одному на каждый chat_id). Эти функции подключаются из внешнего файлаsession_func.R.Обновлён
start_handler(): Теперь при вызове/startбот сначала проверяет, есть ли сохранённый .rds-файл сессии для данного пользователя. Если есть — загружает его. Если нет — создаёт новый чат-объект и сохраняет его.Обновлён
message_handler(): Здесь всё то же, что и раньше, но теперь после каждого запроса дополнительно сохраняется обновлённый объект чата обратно в.rds. Это важно, чтобы вся история общения сохранялась между сессиями.
Таким образом, теперь бот умеет “помнить”, о чём вы говорили с ним ранее, даже если он был выключен или перезапущен — очень полезно для долгосрочного взаимодействия с пользователями.
2.3.2 Конвертация ответа от LLM в Telegram MarkdownV2
Описанный выше код будет вполне корректно работать при простых ответах от LLM. Но есть одна проблема, с которой сталкиваются почти все разработчики, которые пытаются переслать полученный от LLM ответ сразу в telegram - Bad Request: can't parse entities. Дело в том, что все LLM отдают свой ответ в разметке GitHub-flavored Markdown (GFM), а telegram требуеют свою Markdown разметку, причём довольно строго относится к ошибкам в ней. У Telegram строгие правила экранирования множества символов и немного иной набор допустимых конструкций.
Один из вариантов решения “в лоб” - просто поменять разметку в parse_mode на HTML, она обычно не возвращает ошибку Bad Request: can't parse entities, но и само сообщение полученное в Telegram будет выглядеть сырым, с элементами разметки, смотреться это будет откровенно говоря не презентабельно.
Писать собственный конвертер GFM -> Telegram MarkdownV2 задача достаточно непростая, но можно использовать готовое решение, правда написанное на Python - модуль telegramify-markdown.
Для начала установите пакет reticulate, который позволяет выполнять python код внутри R. Далее, если у вас не установлен Python запустите процесс установки:
install.packages('reticulate')
# Импортировать модуль
library(reticulate)
# установка python
install_miniconda()
# Создать окружение и установить пакет
virtualenv_create("r-telegram-env")
use_virtualenv("r-telegram-env")
py_install("telegramify-markdown")Далее мы можем написать R обёртку:
# Импортировать модуль
telegramify <- import("telegramify_markdown")
# Функция на R
markdown_to_telegram <- function(markdown_text,
max_line_length = NULL,
normalize_whitespace = FALSE) {
converted <- telegramify$markdownify(
markdown_text,
max_line_length = max_line_length,
normalize_whitespace = normalize_whitespace
)
return(converted)
}И использовать её для конвертации полученного от LLM ответа в корректный Telegram MarkdownV2 внутри нашего message_handler:
# отправляем запрос пользователя в LLM
response <- chat$chat(user_message, echo = FALSE)
# конвертируем в Telegram MarkdownV2
tg_response <- markdown_to_telegram(response)
# отправляем в чат полученный от LLM ответ
bot$sendMessage(
chat_id = chat_id,
text = tg_response,
parse_mode = 'MarkdownV2'
)Функция markdown_to_telegram() делает следующее:
1. Парсит Markdown в AST (Abstract Syntax Tree) с помощью библиотеки mistune
2. Рендерит каждый элемент отдельно: заголовки, ссылки, списки, таблицы, код
3. Сохраняет контекст форматирования: отслеживает, находимся ли мы внутри жирного текста, курсива и т.д.
4. Правильно обрабатывает вложенности: например, bold italic bold bold
5. Экранирует только нужные символы: внутри кода не экранирует, внутри ссылок экранирует по-особому
6. Обрабатывает Latex: распознает формулы \(...\) и \[...\]
7. Работает с таблицами: конвертирует их в читаемый формат
8. Обрабатывает цитаты: правильно форматирует > блоки
9. Тестирована на тысячах реальных случаев
Т.е. является полноценным, стабильно работающим, и постоянно обновляющимся конвертером полученных от LLM ответов в корректный Telegram MarkdownV2.
2.4 Заключение
Теперь ваш бот — это не просто скрипт, а интеллектуальный собеседник с “долгой памятью”. Мы научили его узнавать пользователей и сохранять контекст в RDS-файлы.
Однако пока наш бот заперт внутри своих знаний и того, что мы передали ему в промпте. Он не может заглянуть в вашу базу данных или прочитать свежую Google-таблицу. В следующей главе мы сотрем эти границы. Мы разберем протокол MCP (Model Context Protocol) и научим бота выходить во “внешний мир”: выполнять ваши функции на R, ходить по API и работать с реальными файлами на сервере. Время дать вашему ассистенту настоящие руки!
2.5 Вопросы для самопроверки
Почему нельзя использовать один глобальный объект chat для всех пользователей Telegram-бота?
Контексты сообщений от разных людей перемешаются в одной сессии. Модель будет пытаться связать вопрос Пользователя Б с ответом, который она только что дала Пользователю А, что приведет к путанице и потере логики диалога.Какую роль играет ID чата (
Он служит уникальным ключом. По этому идентификатору бот понимает, какой именно объект чата (из списка в памяти или из файла RDS) нужно подтянуть для текущего собеседника.chat_id) в архитектуре хранения сессий?Зачем в системном промпте бота рекомендуется ограничивать длину ответа (например, до 3000 символов)?
Это техническая подстраховка. Лимит одного сообщения в Telegram — 4096 символов. Если модель сгенерирует слишком длинный текст (например, большой кусок кода с пояснениями), бот выдаст ошибку при попытке отправить такое сообщение.В чем преимущество хранения объектов чата в RDS-файлах по сравнению со списком в оперативной памяти?
Это обеспечивает «персистентность» (постоянство) данных. Если сервер или скрипт перезагрузится, данные в оперативной памяти (списокsessions) сотрутся, а файлы на диске останутся. Бот сможет продолжить диалог с того же места.Какая функция в пакете
Методellmerотвечает за отправку сообщения и получение ответа?$chat()(например,chat$chat(user_message)). Он отправляет текст провайдеру LLM и возвращает строку с ответом.Зачем ограничивать длину ответа и как это сделать надежнее всего?
Лимит сообщения в Telegram — 4096 символов. Надежнее всего использовать комбинацию: просить модель быть краткой в system_prompt и выставлять жесткий лимит через api_args = list(max_output_tokens = 1500).